

Oracle 23ai introduce el tipo vector, como un nuevo tipo de dato para tabla para poder manejar toda la potencia de la inteligencia artificial dentro de las bases de datos.
Un vector es una secuencia de números, llamados dimensiones. A nivel de IA representaría la semántica de los datos para una imagen, un documento, un video o un audio.
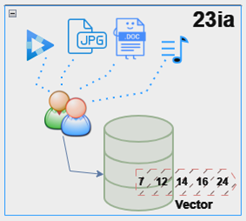
Es importante recalcar que el vector representa una versión numérica del contenido semántico de los datos. No se trata de palabras de un documento o de los pixeles de una fotografía. Esto da una gran ventaja al realizar búsquedas de contenido directamente sobre datos no estructurados.
A esta técnica de convertir una imagen o un audio o documento a vector se llama técnica de vectorización.
Pero, ¿qué podemos conseguir si usamos vectores en un negocio? Simplicidad.
No haría falta guardar todos los archivos multimedia en base de datos, simplemente vectorizaríamos esa información para almacenar únicamente los vectores. Esto se realiza mediante un proceso llamado embedding, que consiste en realizar transformaciones de esos datos mediante un patrón existente. Por ejemplo: las fotos de gatos transformarán según tipo de pelo, color, raza, sexo, tamaño, etc. en un conjunto de números para cada atributo.
Estos embedding permiten entonces leer un dato o una imagen o un vídeo, en su versión simplificada como un vector. De hecho, no todos los vectores tienen el mismo tamaño.
Para ilustrar cómo se trabaja con vectores en esta nueva versión, vamos a realizar un ejemplo de búsqueda de similitud en dato no estructurado. En este caso, será un conjunto de imágenes.
Te propongo descargarte la máquina virtual de Oracle23ia Developers Free Edition desde el sitio de Oracle Developer’s Day, en este enlace.
Seguiremos este flujo para buscar similitudes entre las distintas imágenes:
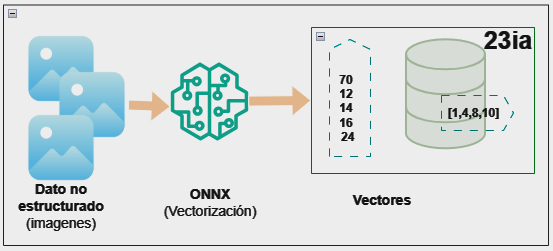
Lo primero que tenemos que hacer es buscar un modelo ONNX (Open Neural Net Exchange) para vectorizar las imágenes. Estos modelos son los que permiten realizar el embedding con información de inteligencia artificial previamente entrenada.
Dejo por aquí un repositorio en GitHub Onx Model Zoo con multitud de modelos ONNX.
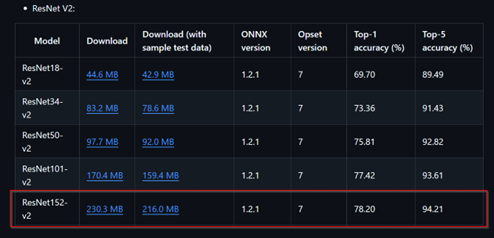
El modelo ONNX que vamos a usar es el siguiente:

En concreto, utilizaremos la versión ResNet152-v2
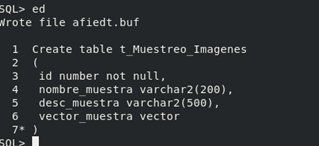
Lo primero que vamos a hacer para convertir datos no estructurados (imágenes) en vectores es definir una tabla para almacenar esos vectores en un schema para aislar nuestra prueba en nuestra base de datos 23ia.

Hemos creado el usuario testvector con el permiso create mining model. Este permiso es necesario para crear modelos.
La tabla que hemos definido para guardar nuestras imágenes es la siguiente:
En nuestro caso, como vamos a utilizar imágenes aleatorias sin un tamaño fijo a nivel de vector. No voy a especificar el número de dimensiones o el formato (ambos opcionales) con el fin de poder introducir vectores diferentes.
Bien, llegados a este punto nos faltaría definir la clase Python para generar los vectores, haciendo el embedding con un modelo que va a capturar la semántica. Este modelo es especifico para trabajar con animales y en este caso lo vamos a hacer desde Python. La versión de Python necesaria es la 3.8 y una vez descargada e instalada hay que marcarla como versión por defecto mediante el comando “sudo alternatives –config python3
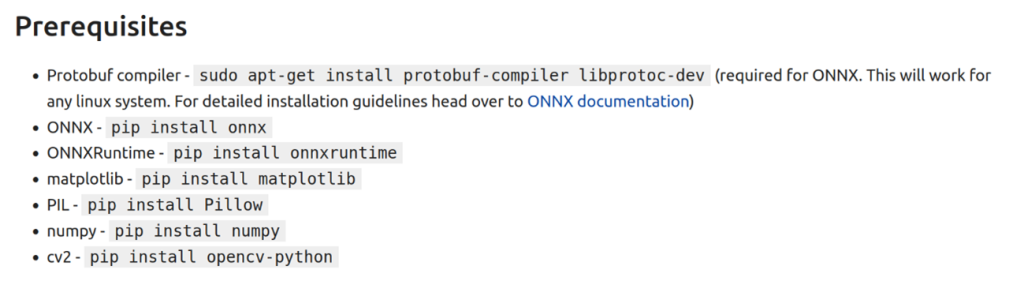
El siguiente paso sería instalar los Prerequisitos que nos piden para utilizar el modelo ResNet.
En Python vamos a usar unas funciones especificas para importar ese modelo en formato onnx y por supuesto para conectar a la base de datos.
Las imágenes que vamos a usar serán las siguientes:

Vamos a tomar 15 fotos (256×256) agrupadas en tres animales: perro, tortuga y pato. Estas fotos son las que vamos a vectorizar e insertar en nuestra tabla que hemos creado previamente.
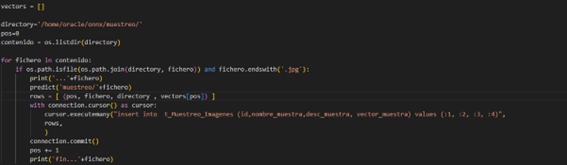
Aquí podemos ver parte del código de Python leyendo el directorio donde se encuentran las imágenes, invocando en cada iteración la función que genera el embedding, capturando la semántica de cada foto que se encuentre en ese directorio y de ahí el vector. Cada vector generado tendría la semántica de la foto.
Una vez que hemos obtenido el vector, lo grabaríamos en la tabla:
Puedes descargar la clase de Python aquí.
Ejecutamos la clase en nuestro directorio, importante tener aquí los modelos onnx. Esta sería el contenido del directorio donde tendríamos el modelo, junto las imágenes y la clase Python “load_vector.py”
Ejecutamos la clase “python3 load_vector.py”
Nuestra tabla ahora tiene 15 filas donde cada fila representa una imagen.

También podemos ver el aspecto que tiene el vector de la foto:
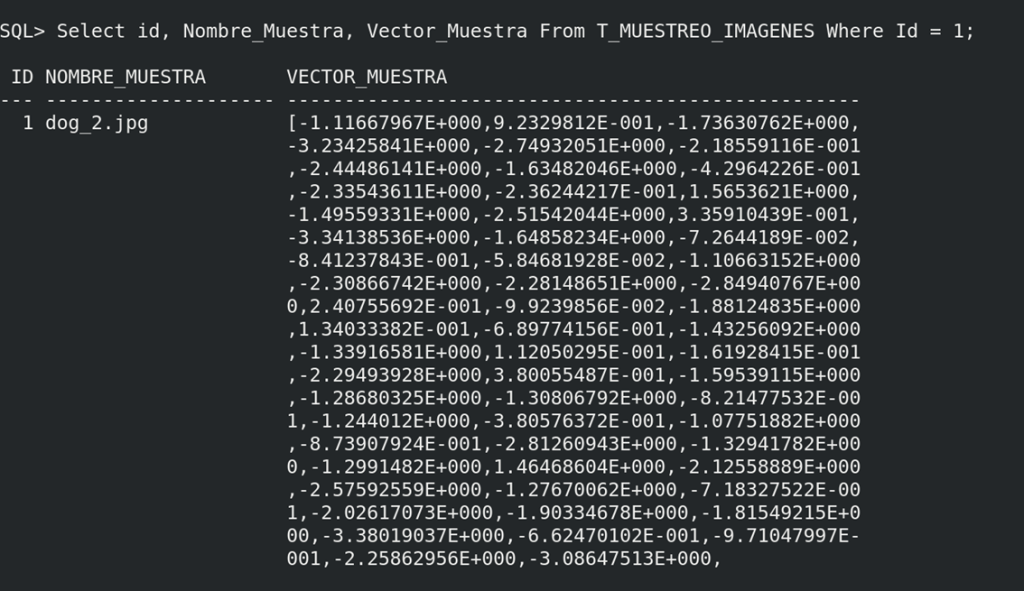
Con esta información podemos hacer la primera búsqueda de similitud.
Utilizaremos una de esas fotos para usarla como filtro para hacer una búsqueda de distancia y ser capaces de identificar las otras fotos de ese animal y ver si efectivamente son las que más cercanas están en ese espacio multidimensional, en esas X posiciones.
Esto son los datos que tenemos en nuestra tabla:
Definimos una variable de tipo vector para almacenar ahí la información de la foto que vamos a realizar la búsqueda de similitud.
Además, nos apoyaremos en la función VECTOR_DISTANCE para realizar la búsqueda de similitud. Esta función tiene implementado una serie de algoritmos en el motor de la base de datos y nos ayudan hacer búsquedas semánticas cercanas, nunca va a ser exacta porque en este concepto de vectores, es muy difícil que dos vectores coincidan. Esta función acepta dos vectores por parámetros y devuelve la distancia que hay entre ellos.

Con la función VECTOR_DISTANCE realizamos la búsqueda de similitud de los 4 primeros que encuentre.

La primera foto que nos encuentra es la misma que estamos usando para realizar el filtro. Las tres siguientes que ha encontrado como más cercanas son el mismo animal en diferentes ámbitos.
Repetimos el mismo proceso, pero con otro animal:

La primera foto que nos encuentra es la misma que estamos usando para realizar el filtro. Las tres siguientes que ha encontrado como más cercanas son el mismo animal en diferentes ámbitos.
Con esto hemos podido observar que los vectores han sido capaces de capturar la información que había en las fotos y sin trabajar directamente con el archivo, sino con el vector, Oracle ha sido capaz de encontrar similitudes en ese espacio.