

Imagina que planificas una migración de una base de datos entre dos servidores.
Import FULL a una BBDD nueva.
Tienes muchos motivos para «reorganizar» toda la bbdd: Un tablespace de SYSTEM de más de 60GB, otro de SYSAUX con más de 40GB… ya sabes, auditorías que se escribieron donde no era el mejor sitio, un montón de tablas con millones de filas que nunca se han reorganizado, lo mismo con los índices,…
Así que creas un entorno nuevo y lanzas un impdp con NETWORK_LINK, con un FLASHBACK_TIME=»systimestamp» y un buen paralelismo.
Ponle que PARALLEL=16, o PARALLEL=32. Que la máquina tiene un montón de CPUs.
Aquello arranca que es un frenesí.
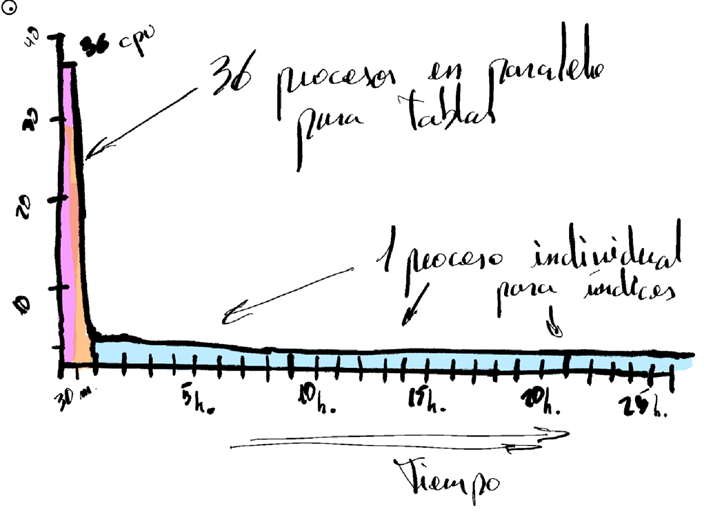
En 26 minutos tienes todos los datos de tablas en destino.
Y justo cuando te preparas un whiskazo para saborear las mieles de tu éxito, te queda lo peor: índices, constraints y estadísticas.
Y esos 26 minutos se convierten en 26 horas. Y el flashback rozando el ORA-1555.
Pues, si piensas que los 32 procesos empiezan a colisionar entre sí… pues no va por ahí. Todo lo contrario.
Para empezar: los índices los crea sólo un worker.
Lo siguiente es que impdp trata la creación de los índices sin paralelismo. Así como lo oyes.
En realidad, está hecho con toda la intención. Serializando la creación de índices evitas que se lancen concurrentemente varios índices sobre la misma tabla y te libras de los múltiples bloqueos «TM» que de dejan la library caché con una contención que hace que el import pierda muchísimo tiempo en la gestión de tanto bloqueo de objeto simultáneo.
Esto ha sucedido siempre. En versiones anteriores (en 11g… bug 8604502 por si tienes curiosidad), los índices al importarse se creaban con PARALLEL 1 y así se quedaba en destino aunque tuvieran definido otro nivel de paralelismo en origen. Posteriormente, corrigieron este error añadiendo un ALTER INDEX tras la creación con PARALLEL 1, para dejar el paralelismo correspondiente al origen.
En el caso que te describo, no había objetos particionados en origen, pero me consta que, en índices particionados, impdp también dedica un worker en serie por cada partición, con lo cual seguimos teniendo mucho desaprovechamiento de recursos.
Por lo tanto, el frenesí de 32 procesos, rápidamente se convierte en un único thread, creando índices y levantando constraints secuencialmente.
Para evitar todo esto, aquí te paso mi receta casera, para que puedas darle un empujón de paralelismo (a mano) a tu import Data Pump y sarle ese «boost» que necesitas.
1.- Carga sólo los datos primero.
En la carga de datos, métele todo el paralelismo que puedas. En mi caso, como unos 500GB de datos se pasaron en 26 minutos via dblink. Paralelismo a tope.
Excluye índices, constraints y estadísticas. Te las llevarás luego.
impdp network_link=BBDD_ORIGINAL_LINK full=yes logfile=migracion_solo_datos.log parallel=32 exclude=STATISTICS,CONSTRAINT,REF_CONSTRAINT
2.- Genera un fichero de índices, y luego otro con las constraints.
impdp network_link=BBDD_ORIGINAL_LINK schemas=LISTA_USUARIOS_SEPARADOS_POR_COMA sqlfile=indices_ddls.sql include=INDEX
impdp network_link=BBDD_ORIGINAL_LINK schemas=LISTA_USUARIOS_SEPARADOS_POR_COMA sqlfile=constraints_ddls.sql include=CONSTRAINT,REF_CONSTRAINT
3.- Edita el fichero indices_ddls.sql para corregir los PARALLEL 1.
Verás que en el fichero indices_ddls.sql todos los índices se crean de la siguiente forma:
— Primero crea el índice con PARALLEL 1
CREATE UNIQUE INDEX «USUARIO».»INDICE1″ ON «USUARIO».»TABLA1″ («COLUMNA1»)
PCTFREE 10 INITRANS 2 MAXTRANS 255
STORAGE(INITIAL 131072 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 –> Esta parte depende de la cláusula de STORAGE de origen.
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE «INDICES»
PARALLEL 1 ; –> Aquí tienes el PARALLEL 1 que te interesa cambiar
— Y posteriormente le cambia el valor al que tuviera en origen
ALTER INDEX «USUARIO».»INDICE1″ PARALLEL ;
Si lo haces con «Buscar y reemplazar», remplaza PARALLEL 1 por PARALLEL.
Si lo hace con vi, :%s/PARALLEL 1/PARALLEL/g
4.- Prepárate el script de gather_stats.
Toda la base de datos estará reorganizada y con objetos nuevos, mejor generarlas de nuevo:
begin
dbms_stats.gather_database_stats(
estimate_percent =>dbms_stats.auto_sample_size,
degree =>dbms_stats.auto_degree, — Paralelismo automático
method_opt =>’for all indexed columns size auto’,
cascade => true);
end;
/
5.- Localiza las tablas de mayor volumen y mayor número de índices y de constraints en el entorno origen.
Aquí tienes un ejemplo de por dónde sacarlas. Si necesitas localizar objetos particionados, haz lo mismo cruzando DBA_IND_PARTITIONS.
column owner format a30
column segment_name format a30
column segment_type format a15
select s.owner, segment_name, s.segment_type, round(s.bytes/1024/1024/1024) GB, count(*) TOTAL_INDICES
from dba_segments s, dba_indexes i
where s.segment_name=i.table_name and s.owner=i.table_owner
and s.bytes/1024/1024/1024>3
and s.owner in (‘LISTA_USUARIOS’)
and s.segment_type=’TABLE’
group by s.owner, segment_name, s.segment_type, round(s.bytes/1024/1024/1024)
order by 4 desc,5 desc ;
select s.owner, segment_name, s.segment_type, round(s.bytes/1024/1024/1024) GB, count(*) TOTAL_CONSTRAINTS
from dba_segments s, dba_constraints c
where s.segment_name=c.table_name and s.owner=c.owner
and s.bytes/1024/1024/1024>3
and s.owner in (‘LISTA_USUARIOS’)
and s.segment_type=’TABLE’
and c.constraint_type in (‘P’,’R’)
/* Sólo te preocupan las constraints PRIMARY KEY y FOREIGN KEY */
group by s.owner, segment_name, s.segment_type, round(s.bytes/1024/1024/1024)
order by 4 desc,5 desc ;
6.- Haz tu artesanía con los índices.
Como no es muy conveniente que lances la creación en paralelo de todos los índices de una misma tabla, pues generarás contención en la lectura de esa tabla y un montón de esperas, te recomiendo que «aisles» los índices de estas tablas grandes que hayas obtenido en el anterior script
Crea un script de índices por cada tabla una de esas tablas grandes y prioriza las que tienen mayor número de índices y constraints.
7.- Haz tu artesanía también con las constraints.
Estas tablas grandes van a tener una activación de constraints en serie, y también va a ser dura.
Localiza las foreign keys para preparar un script que cree primero las claves primarias de las tablas relacionadas y posteriormente las foreign keys de estas tablas grandes.
Ten en cuenta que no podrás lanzar los scripts de constraints hasta asegurarte que los índices relacionados estén creados, pues son constraints vinculadas a los índices creados previamente. En este script creado en el punto 2 llamado constraints_ddls.sql tendrás primero la creación de todas las primary key seguidas así:
ALTER TABLE «USUARIO».»TABLA» ADD CONSTRAINT «TABLA_PK» PRIMARY KEY («ID»)
USING INDEX «USUARIO».»INDICE_PK» ENABLE;
Y en la segunda parte del script, todas las foreign keys.
ALTER TABLE «USUARIO».»TABLA_REF» ADD CONSTRAINT «FK_TABLA» FOREIGN KEY («COLUMNA»)
REFERENCES «USUARIO».»TABLA» («ID») ENABLE;
Úsalo para crear tus scripts para estas tablas individuales.
8.- En el momento de la importación, hazlo en el siguiente orden:
Primero, la creación de las tablas sin índices ni constraints.
Es lo que has hecho en el punto 1. Añade el flashback_time para que la carga sea consistente por si hay actividad transaccional en origen.
impdp network_link=BBDD_ORIGINAL_LINK full=yes logfile=importacion_tablas.log parallel=32 exclude=statistics,constraint,ref_constraint,index flashback_time=»systimestamp»
Una vez creadas las tablas, lanza los scripts de creación de índices con el paralelismo corregido y, en sesiones distintas, lanza los scripts de creación de índices de estas tablas grandes.
Al tratarse de tablas de gran volumen, sí te interesa que la creación de sus índices se serialice, pero eso no te impide que puedas lanzar simultáneamente los scripts del resto de tablas grandes.
No habrá contención por ddl entre ellas, ya que bloquearán objetos diferentes. Eso sí, si lanzas en varias sesiones el script de creación de todos los índices, sí verás esperas en la creación de los índices de una misma tabla. El primer script bloqueará la tabla y se segundo se quedará en espera para crear el segundo índice de esa misma tabla.
alter session set nls_date_format=’DD-MON-YYYY HH24:MI:SS’;
set timing on
alter session set ddl_lock_timeout=1;
/* Si la tabla está siendo accedida y hay un bloqueo, no es tiempo de ponerse a la espera.*/
spool indices_ddls_1.log
/* Puedes lanzarlo en varias sesiones en paralelo teniendo en cuenta las posibles esperas/contención. */
select sysdate from dual;
/* Los sysdate son sólo por medir cuánto tarda cada script. Ya sabes… */
@indices_ddls.sql
select sysdate from dual;
spool off
alter session set nls_date_format=’DD-MON-YYYY HH24:MI:SS’;
set timing on
alter session set ddl_lock_timeout=1;
spool lanza_indices_TABLA_GRANDE1.log
select sysdate from dual;
@indices_ddls_TABLA_GRANDE1.sql
select sysdate from dual;
spool off
Una vez los índices de la tabla grande se hayan creado, podrás lanzar los scripts de las constraints. No olvides que las claves primarias necesitarán que sus índices estén creados previamente.
alter session set nls_date_format=’DD-MON-YYYY HH24:MI:SS’;
set timing on
alter session set ddl_lock_timeout=1;
spool lanza_constraints_TABLA_GRANDE1.log
select sysdate from dual;
@constraints_ddls_TABLA_GRANDE1.sql
select sysdate from dual;
spool off
Una vez termines con los índices y constraints de las tablas grandes, si el tiempo total de importación te preocupa mucho, ve lanzando el script de generación de estadísticas para que vaya haciendo el gather de las tablas grandes. Gracias al valor de dbms_stats.auto_degree, también verás ahí un aprovechamiento del paralelismo de procesos en la recopilación de estadísticas.
Con todo este «paralelismo artesanal» vas a terminar la importación en un tiempo record.
El resumen de mi importación artesanal que tardaba 26 horas en ejecutarse, con esta receta artesanal, quedó así:
Tiempos finales (ejemplo de mi última migración)
Tiempo inicial de impdp estándar con PARALLEL 32 pero generación de índices y constratints secuencial incluyendo un DBMS_STATS final: 14h 36minutos.
Tiempo de impdp seguido en este artículo desglosado.
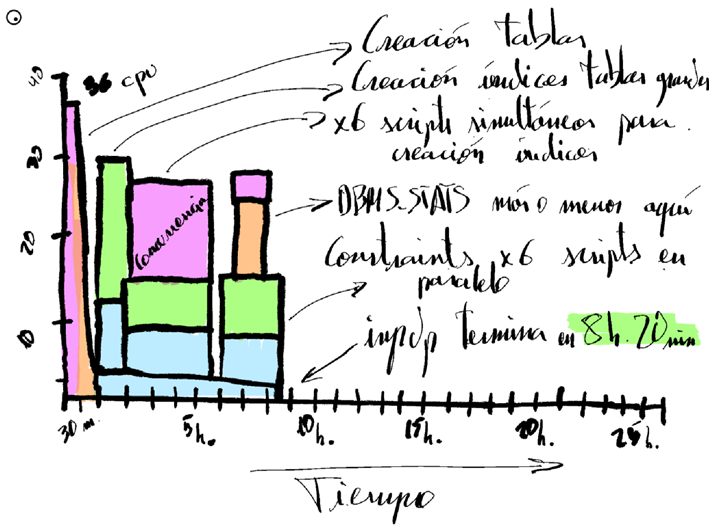
T1 – Inicio migración.
Creación de tablas y filas -> 26 minutos.
T2 = (T1+26 minutos) – Con las tablas creadas con filas.
Lanzamiento de índices (general) con 6 sesiones concurrentes. -> 4h 25 minutos
Lanzamiento de índices (tablas grandes de aprox. 50GB cada una) lanzando 4 sesiones concurrentes. -> 1 hora
Lanzamiento de índices (tablas medianas de aprox 5GB data una) lanzando 2 sesiones concurrentes -> 35 minutos.
T3 = (T1+26 minutos + 4h 25 minutos)
Lanzamiento de las constraints con 6 sesiones concurrentes (las constraints previamente creadas por las tablas grandes quedan excluídas) -> 3h 30 minutos.
Tiempo total de importación: 26 minutos + 4h 25 minutos + 3h 30 minutos = 8h 20 minutos.